
MySQL Join算法
Simple Nested-Loop Join
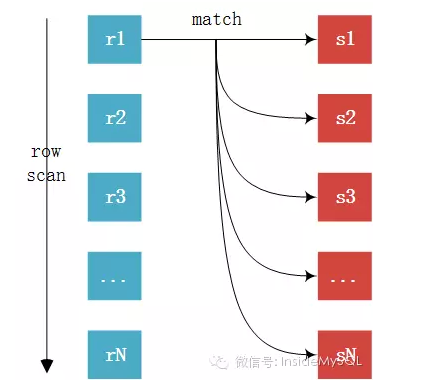
Simple Nested-Loop Join的算法简单粗暴,其通过驱动表中的每一条记录与被驱动表中的记录进行对比,假设有表A和表B,表A有10000条记录,表B有1000条记录,那数据对比的次数就等于10000*1000次,效率是非常低下的。
Block Nested-Loop Join
MySQL当然不会采用Simple Nested-Loop算法,而是使用了Block Nested-Loop Join的算法。该算法的流程是:
- 把表A的数据读入线程内存join_buffer中
- 扫描表B,把表B的每一行取出来,跟join_buffer中的数据进行对比,满足join条件则作为结果集的一部分返回
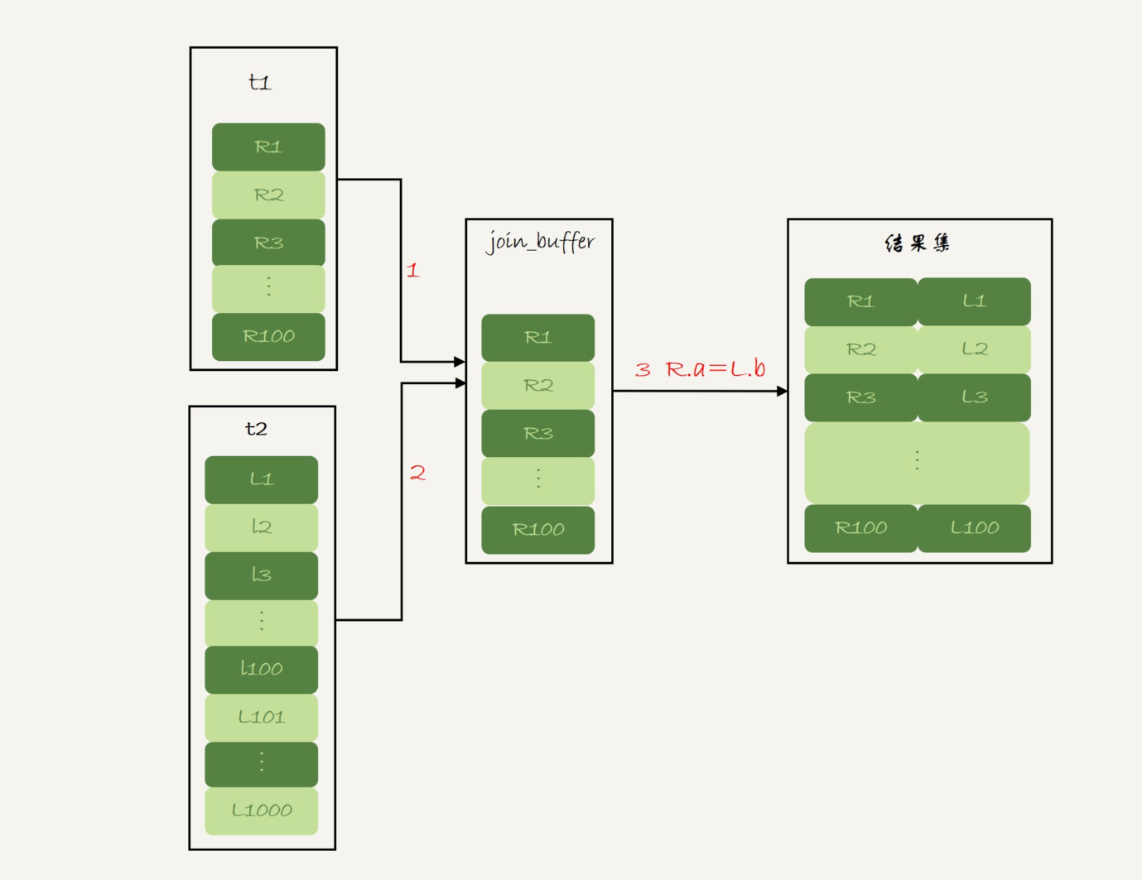
在这个过程中,由于join_buffer是无序组织存放的,因此对表B的每一行,都要进行对比,总对比的次数也是表A的行数乘以表B的行数。这与simple Nested-Loop是一样的,但Block Nested-Loop是在内存中完成的,因此性能上会更好。
join_buffer是由参数join_buffer_size控制的,默认为256K。如果数据量较大,一次性放不下表A的数据,这时会采用分段放的方式,简单来说就是在join_buffer写满后立马与表B进行对比返回结果集,再将join_buffer清空进行后面数据的对比,直到对比完成。虽然对比次数不变,但由于进行了分段,驱动表的大小会影响扫描行数,驱动表越大,扫描行数就越多,因此这种情况下应当利用小表作为驱动表。
Index Nested-Loop Join
Index Nested-Loop Join是基于索引进行连接,驱动表通过被驱动表上的索引进行匹配,避免与被驱动表的每条记录都进行对比,减少对比次数,提升Join性能
root@test 14:13: explain select * from t1 straight_join t2 on (t1.a=t2.a); |
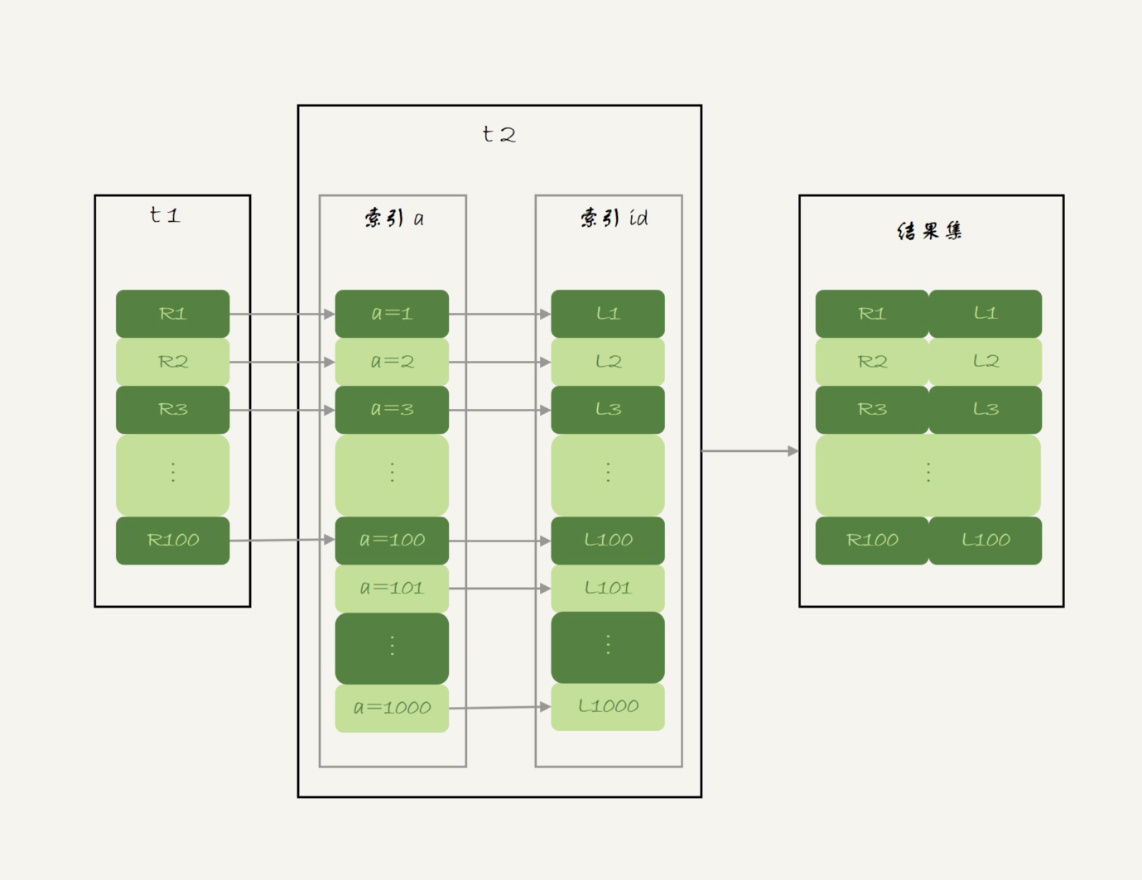
t1是驱动表,t2是被驱动表,t2上的a字段有索引,join使用了该索引,其执行过程如下:
- 从表t1中读取一行记录A1
- 从数据行A1中取出字段a到t2里去查找
- 取出t2中满足条件的行,与A1组成一行作为结果集
- 重复上述3个步骤,直到t1遍历完成
这个时候怎么去选择驱动表与被驱动表呢?在上面的例子中,驱动表走的是全表扫描,而被驱动表走的是索引树搜索,应该将小表作为驱动表
Batched Key Access
在正式介绍BKA之前,我们需要先了解MRR优化,这个优化主目的主要是尽量使用顺序IO。MRR在通过二级索引获取到主键ID后,将ID值放入read_rnd_buffer中,然后对其进行排序,利用排序后的ID数组遍历主键索引查找记录并返回结果集,优化了回表性能。
理解了MRR优化后,我们就来看看Batched Key Access(BKA)算法,BKA算法是对INDEX Nested-Loop Join算法的优化。INDEX Nested-Loop的执行逻辑是从驱动表中一行行取出join字段,再到被驱动表去做join,这样每次都是匹配一个值,无法使用MRR优化。这时可以参考Block Nested-Loop算法将驱动表的数据临时存放在Join buffer中,这时就可以通过MRR优化来提升性能。
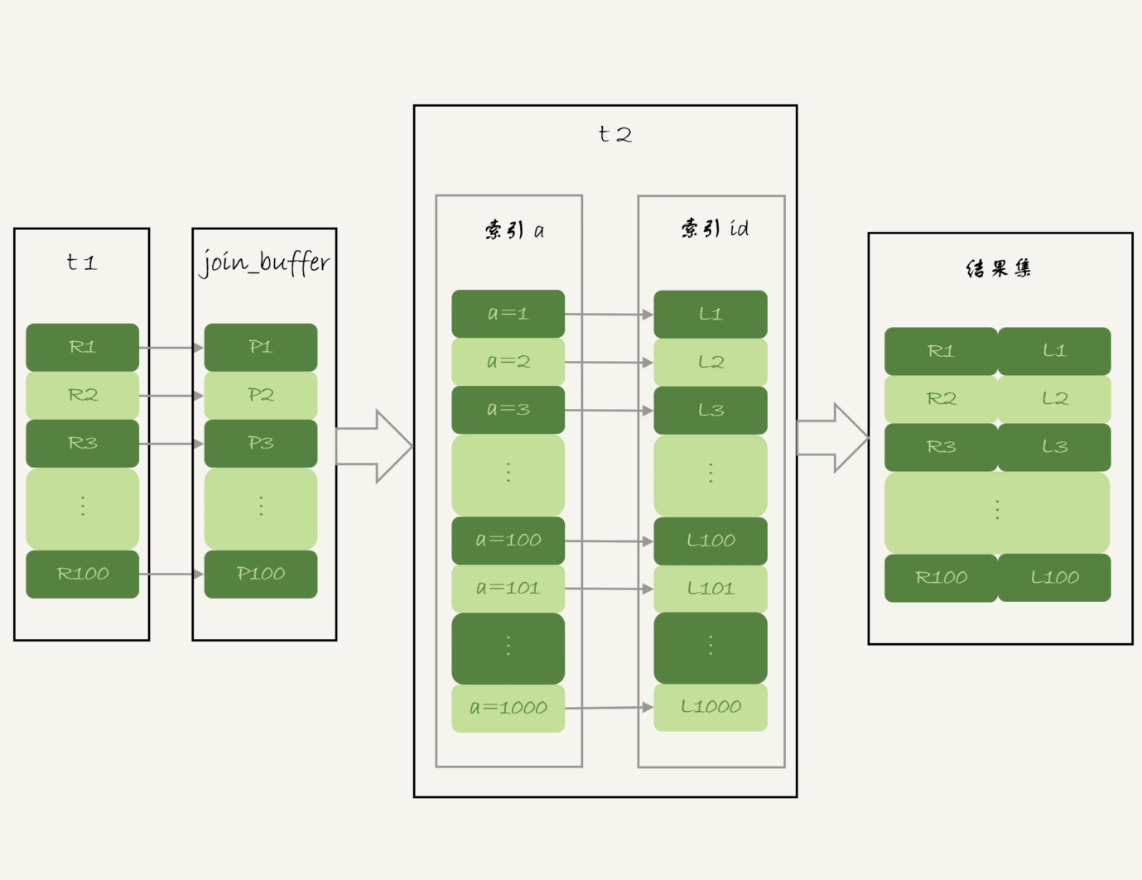
如果想要启用BKA优化算法的话,需要进行设置
set optimizer_switch='mrr=on,mrr_cost_based=off,batched_key_access=on'; |
MariaDB Hash Join
MariaDB支持classic hash join,它根据join buffer中的数据创建哈希表,被驱动表通过哈希算法进行查找,从而在Block Nested-Loop Join的基础上进一步减少被驱动表的比较次数,提升Join性能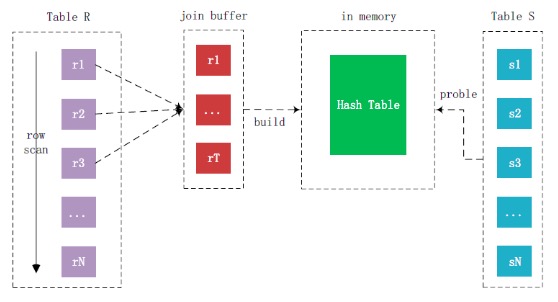
要使用Classic Hash Join,需要将join_cache_level设置为大于等于4的值,并显示打开优化器选项
set join_cache_join=4; |
优化建议
- Block Nested-Loop Join算法的性能问题不仅仅是因为会导致IO压力,由于频繁扫描表可能会导致业务数据无法进入LRU链表中的young区,内存命中率降低。这种情况下,建议给被驱动表的join字段添加索引,把Block Nested-Loop Join转换为Batched Key Access
- 在使用Join时,应该选择小表作为驱动表
)